LLaMa, acronimo di Large Language Model Meta AI, è un modello linguistico basato sull'intelligenza artificiale, sviluppato da Meta, l'azienda madre di Facebook, WhatsApp e Instagram. Questo modello è stato concepito per rispondere alla crescente esigenza di modelli linguistici più accessibili e versatili, con l'intento di rendere la tecnologia dell'intelligenza artificiale più accessibile a ricercatori e sviluppatori a livello globale.
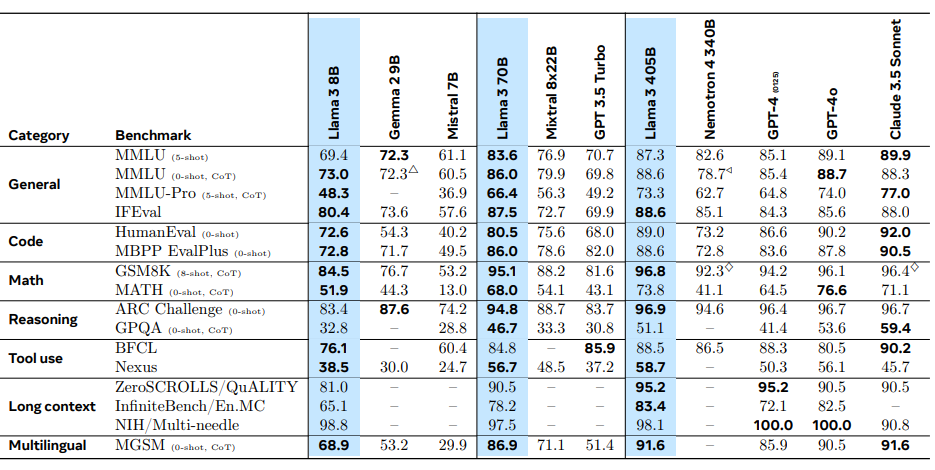
L'ultima versione disponibile del modello è Llama 3.1, sviluppato da Meta, è stato rilasciato il 23 Luglio 2024. Questo modello open source fa parte della famiglia Llama che include versioni da 8B , 70B e 405b, parametri.
In questo playground esploreremo e metteremo alla prova le capacità e i casi d'uso di Llama 3.1 70B, fornendo una panoramica completa basata sulle informazioni più recenti disponibili.
Non perdere l'opportunità di rimanere all'avanguardia
Iscriviti a Marketing Hackers per accedere a scoperte pionieristiche, case study illuminanti, tutorial pratici, corsi immersivi, webinar coinvolgenti e molto altro ancora.
No spam. Disiscriviti quando vuoi.
Architettura
L'architettura di Llama 3.1 si basa sul modello Transformer, lo stesso utilizzato in Llama 2 e 3. La struttura centrale di Llama 3.1 include una serie di blocchi Transformer, ognuno dei quali contiene un meccanismo chiamato Multi-Head Attention e una Feedforward Neural Network.
Il meccanismo di Multi-Head Attention permette al modello di concentrarsi su diverse parti del testo simultaneamente, migliorando la comprensione delle relazioni tra le parole. La Feedforward Neural Network è un tipo di rete neurale che elabora i dati e genera le risposte. Inoltre, Llama 3.1 utilizza la positional encoding per mantenere l'ordine delle parole in una frase, proprio come nei modelli precedenti.
Capacità del Modello
Llama 3.1 supporta una lunghezza di contesto di 128.000 token consentendo al modello di elaborare e comprendere testi molto più lunghi, rendendolo capace di gestire ragionamenti complessi e contesti estesi.
Rispetto alle versioni precedenti I dati utilizzati per l'addestramento iniziale e posteriore di Llama 3.1 sono stati migliorati sia in quantità che in qualità. Questo include pipeline di pre-elaborazione e curazione più accurate per i dati di pre-addestramento e approcci più rigorosi di controllo qualità e filtraggio per i dati di post-addestramento. I requisiti di calcolo per Llama 3.1 sono stati ridotti passando dai numeri a 16-bit (BF16) a quelli a 8-bit (FP8), questo significa che il modello ora richiede meno potenza di calcolo per funzionare, rendendolo più facile da utilizzare su larga scala.
Modello e Descrizione
Utilizzi Ideali
Llama 3.1 405B Modello open source di alta qualità, ideale per generazione di dati sintetici e testi lunghi.
1. Model distillation per migliorare modelli più piccoli 2. Generazione di testi lunghi 3. Traduzione multilingue 4. Programmazione 5. Matematica 6. Function calling 7. Comprensione avanzata del contesto e ragionamento 8. Decision-making avanzato
Llama 3.1 70B Ottimale per creazione di contenuti, chatbot e comprensione del linguaggio.
1. Creazione di contenuti 2. Chatbot 3. Comprensione del linguaggio 4. Ricerca e Sviluppo (R&D) 5. Applicazioni aziendali 6. Riassunti accurati 7. Classificazione testi 8. Analisi del sentiment 9. Interpretazione delle sfumature linguistiche 10. Generazione di codice 11. Seguire istruzioni
Llama 3.1 8B Adatto per risorse computazionali limitate e bassa latenza.
1. Sintesi dei testi 2. Classificazione testi 3. Analisi del sentiment 4. Traduzione linguistica
Llama 3.1 supporta otto lingue, tra cui inglese, tedesco, francese, italiano, portoghese, hindi, spagnolo e tailandese.
Una delle caratteristiche distintive di Llama 3.1 è la sua capacità di ragionamento avanzata. Il modello è stato ottimizzato per applicazioni di dialogo e può seguire le istruzioni umane in modo più efficace. Questo è ottenuto attraverso tecniche come il fine-tuning supervisionato (SFT), l'apprendimento per rinforzo con feedback umano (RLHF) e Direct Policy Optimization (DPO). Questa ottimizzazione rende Llama 3.1 70B particolarmente abile in compiti che richiedono ragionamento multi-step, ad esempio la tecnica Chain-of-Thought, e risoluzione di problemi complessi.
Chiamata di Funzioni
Questa capacità consente al modello di interagire con sistemi esterni e database, permettendogli di eseguire compiti oltre la semplice generazione di testo. Ad esempio, il modello può recuperare dati specifici dei clienti da un database e generare email di marketing personalizzate basate su tali dati, così come scrivere direttamente nei database o connettersi al web.
Risorse Hardware: Llama 3.1 funziona sul computer di casa?
Llama 3.1 è disponibile in tre versioni: 8B, 70B e 405B, ognuna con requisiti di memoria diversi
Modello
Requisiti di Memoria
Modello 8B
FP16: 16 GB FP8: 8 GB INT4: 4 GB Questo modello è leggero e può essere utilizzato su computer di livello consumer con 8 GB di VRAM GPU. È adatto per sviluppo e distribuzione efficienti.
Modello 70B
FP16: 140 GB FP8: 70 GB INT4: 35 GB Richiede molta memoria. Sebbene sia possibile eseguirlo su computer di livello consumer, necessita di una GPU di fascia alta con molta VRAM.
Modello 405B
FP16: 810 GB FP8: 405 GB INT4: 203 GB Estremamente esigente, richiede un setup multi-nodo o esecuzione a precisione inferiore. Anche con FP8, necessita di molta VRAM.
ℹ️
La memoria si riferisce alle GPU, mentre P16, FP8 e INT4 si riferiscono a formati di precisione numerica utilizzati nelle operazioni di calcolo. Il formato che richiede meno memoria restituisce risultati meno precisi.
Quindi, il modello 8B è il più accessibile per i computer di livello consumer, mentre i modelli 70B e 405B sono più adatti per ambienti specializzati o basati su cloud a causa dei loro elevati requisiti di memoria.
Casi d'Uso Testati
I casi d'uso sono molteplici, ho elencato solo quelli per cui ho esperienza diretta
Riassunti
Il modello può generare riassunti e, come sappiamo, l'ho testato con il metodo . I risultati non sono stati eccezionali rispetto ai modelli proprietari, ma per azioni che non richiedevano una buona scrittura, ma che fossero comprensibili abbastanza per uso interno, ha funzionato benissimo. L'ho usato per riassumere le recensioni di ristoranti da Google Maps in massa per una ricerca di mercato.
Il modello è in grado di generare riassunti, e l'ho testato con il metodo Chain of Density. Sebbene i risultati non siano stati all'altezza dei modelli proprietari, per attività che non richiedono una scrittura di alta qualità, ma testi facilmente comprensibili per un uso interno, si è rivelato molto efficace. L'ho utilizzato per riassumere in massa le recensioni di ristoranti estratte da Google Maps, nell'ambito di una ricerca di mercato.
RAG
Il modello funziona nativamente come sistema di recupero delle informazioni, tecnicamente, Retrieval-Augmented Generation (RAG) in locale. Io lo uso per le indagini OSINT. Trovo e collego le fonti su Obsidian, creo un database vettoriale su Qdrant e poi con i retrievers di Langchain estrapolo solo le informazioni che mi servono. Questa parte è un po' ostica se sei agli inizi, ma mi occuperò di tutti questi aspetti nel tempo.
Se hai apprezzato queste informazioni, aiutaci a crescere. L'obiettivo è essere numerosi e affamati di conoscenza, così da poter chiedere alle aziende sconti, accessi in anteprima, inviti ad eventi, fondi per mantenere il progetto e privilegi per i membri di Marketing Hackers, che sarà per sempre gratuito.
Più siamo e più otterremo. Quindi, se ti piace il progetto, condividilo con la tua rete di colleghi e amici e invitali a iscriversi per diffondere la conoscenza e non rimanere indietro.
Stay Tuned!
⚠️
Se sei un membro di Marketing Hackers, puoi provare il modello intermedio Llama 3.1 70b con i tuoi prompt. Il setup che ho creato per te non ha istruzioni particolari di ruolo, non ho effettuato fine-tuning, e ha una funzione di memoria per mantenere il contesto della chat durante la sessione. Alla fine dei tuoi test, puoi dare un pollice in su o giù per indicarci se le prestazioni del modello ti sono state utili a scopo statistico.
Prova qui se il modello fa al caso tuo
Questo post è solo per i membri
Iscriviti ora per leggere il post e accedere all'intera libreria di post solo per i membri.